Not all outputs are created equal
Command Line commands often print there results right back to the command line.
It might be more desirable to save that output to a file either for easier searching, manipulation or to simple save the result.
The common approach is to ‘redirect’ the STDOUT (usually prints to the command line) to a file.
| |
This works quite well in bash and other linux shells but on Windows Powershell there is a big gotcha.
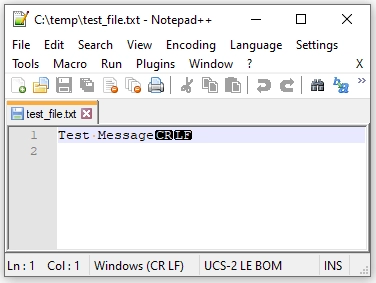
The resulting file has a special encoding called “UCS-2 LE BOM” as opposed to the typical ASCII or UTF-8.
While most text editors will be able to open this just fine, it can cause issues if you’re parsing the file with some custom code (e.g. a Python script)
Running an example command:
| |
And then opening the file “test_file.txt” in Notepad++
Lets run the python script which simply prints the contents of test_file.txt to the command line
| |
This is the result printed to the command line: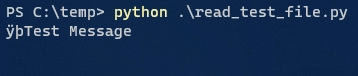
Note the “ÿþ” at the start, this is a result of the Byte Order Mark (BOM), UTF-8 has a variation with a BOM as well but PowerShell’s encoding certainly has it; other than that it seems fine right?
Lets take a look when the file contains multiple lines. I’ll run the aws command to list my S3 buckets, the resulting file (desensitized) is:
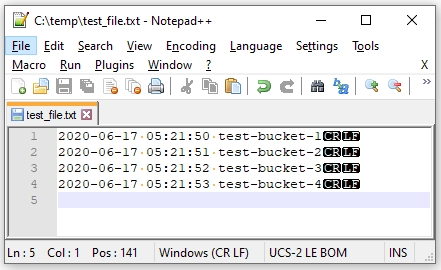
The result of the python script: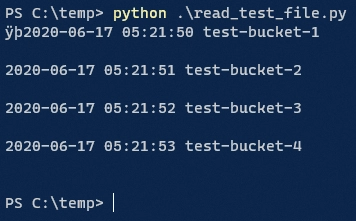
Hmm, not quite right. There seems to be an extra blank line after each newline.
After playing around with the line endings (converting between CRLF and LF) and encodings (between “UCS-2 LE BOM” and “UTF-8”) it seems that “UCS-2 LE BOM” makes python interpret each CRLF as 2 newlines not 1.
LF works as a single newline and both CRLF and LF are only a single newline when encoded as UTF-8.
This is not a complete list of odd behaviours but it shows that if you are not careful, it can cause issues with your scripts.
Thankfully there is a solution!
“UCS-2 LE BOM” is a legacy subset UTF-16 (mostly). You can solve both the BOM issue and the double newline issue by setting the encoding to “utf-16” when you open the file (at least in python):
| |